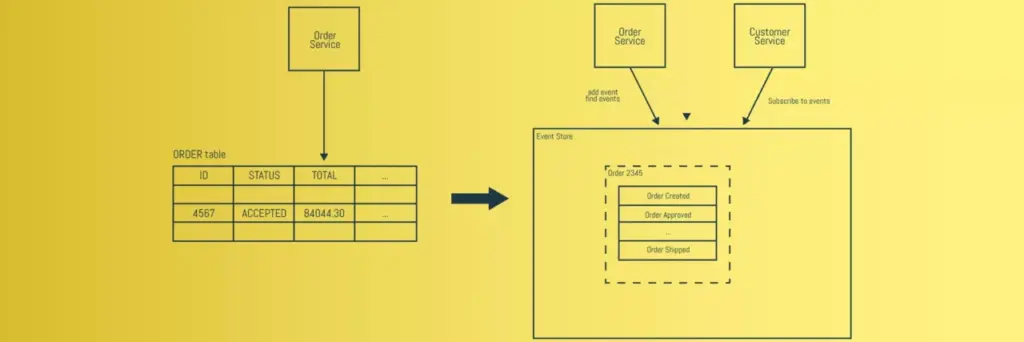
The diagram above outlines our solution architecture. We’ve chosen two business events: ‘Order Placed’ and ‘Payment OK’. These events carry limited information, dictated by what’s needed needed to move the process forward. The ‘Order Placed’ event only carries an ID, whereas the ‘Payment OK’ event carries an ID and additional context information, such as the order ID. In addition, we have a data event, ‘Order Data’, that contains the full state of an order, available to any component requiring a copy of the data. In our scenario, the Payment and Warehouse components consume this event to ensure system resilience, as they need this data to complete their functions.
Those different components also listen to business events to determine when to trigger specific functions. Could we have included all data within the business events? Certainly, but remember that the goal of these business events is not primarily data propagation. I advise against mixing these two uses, as they address completely different problem scopes.
This distinction becomes more apparent when we incorporate changes. Let’s assume a new requirement to incorporate a ‘marketing’ component into the process. We plan to implement a feature that sends a discount coupon for the next order to customers who place orders over €100 for a specific product.
In the example above, nothing needs to change in the existing architecture to accommodate this new functionality. The new functionality can be implemented by extending the current system. The new marketing component will listen to the “order placed” event. Depending on its resilience requirements, it either listens to the ‘Order Data’ event and has all the information locally, or it retrieves data synchronously from the order component as shown here. Chances are high that that the data event contains all necessary order information since that’s its purpose. The business event also carries enough information to continue the processing.
If both these events were merged into one, this extension wouldn’t be as straightforward. There would likely be endless debates over what state the single event should carry to keep it lean and efficient. Why? Because it would have to serve two masters: controlling a business process and propagating state data.