One thing we could do to solve this issue is by just directly querying the other micro service via a HTTP REST API call. Although we could easily do this, it leads to coupling of both micro services. In fact, we are performing a distributed join over HTTP and before we know it, we’ve created a distributed monolith.
To overcome this issue, we can duplicate the relevant data. Again, this could be done by simply issuing a command to the responsible micro service to update the reference via a HTTP REST API call. For example, the order micro service commanding the customer micro service to update the reference. In order to keep the data consistent we should also update the data atomic. We could make use of distributed transactions via a 2-phase commit. However, this is not recommended as the 2-phase commit is synchronously (a blocking operation). In a single database, transactions are fast. But due to the distributed nature of micro services, the delay will be longer.
We could solve this problem by implementing the Saga pattern: the distributed transaction is fulfilled by asynchronous local transactions on all related micro services. If any microservice fails to complete its local transaction, the other microservices will run compensation transactions to rollback the changes.
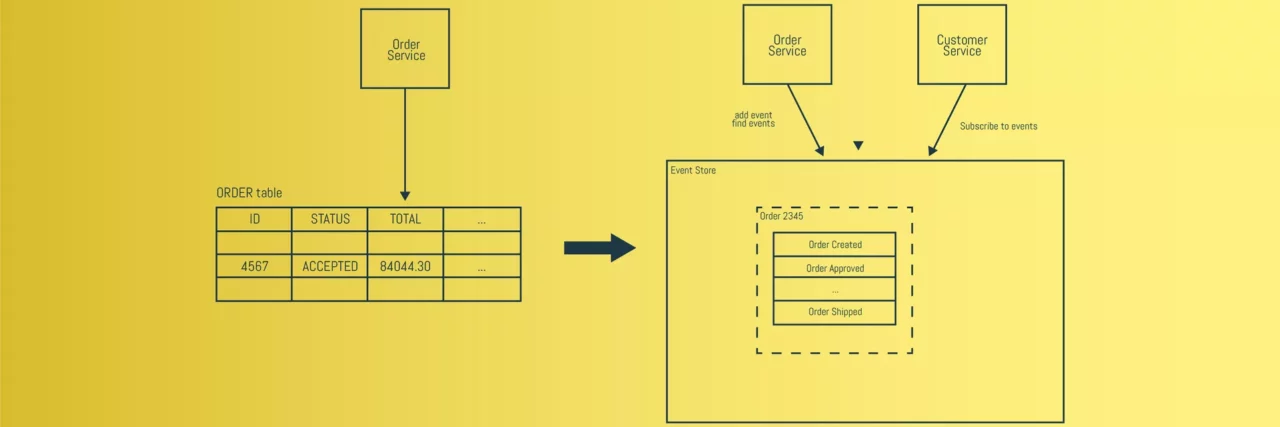
Although this is a commonly used pattern to solve transactional problems within the micro services world, in this blog we examine Event Sourcing with Event Driven Architecture as an alternative.