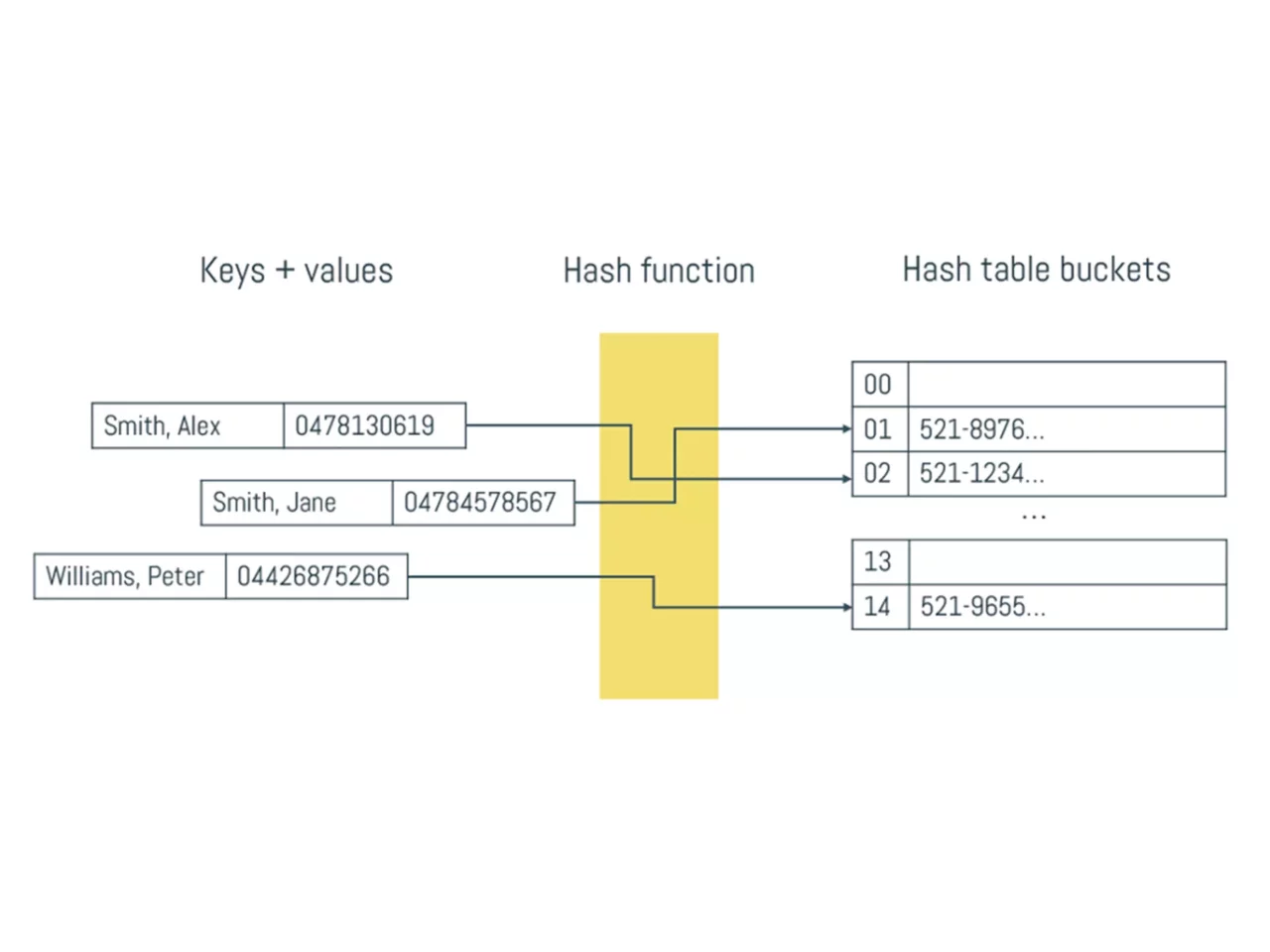
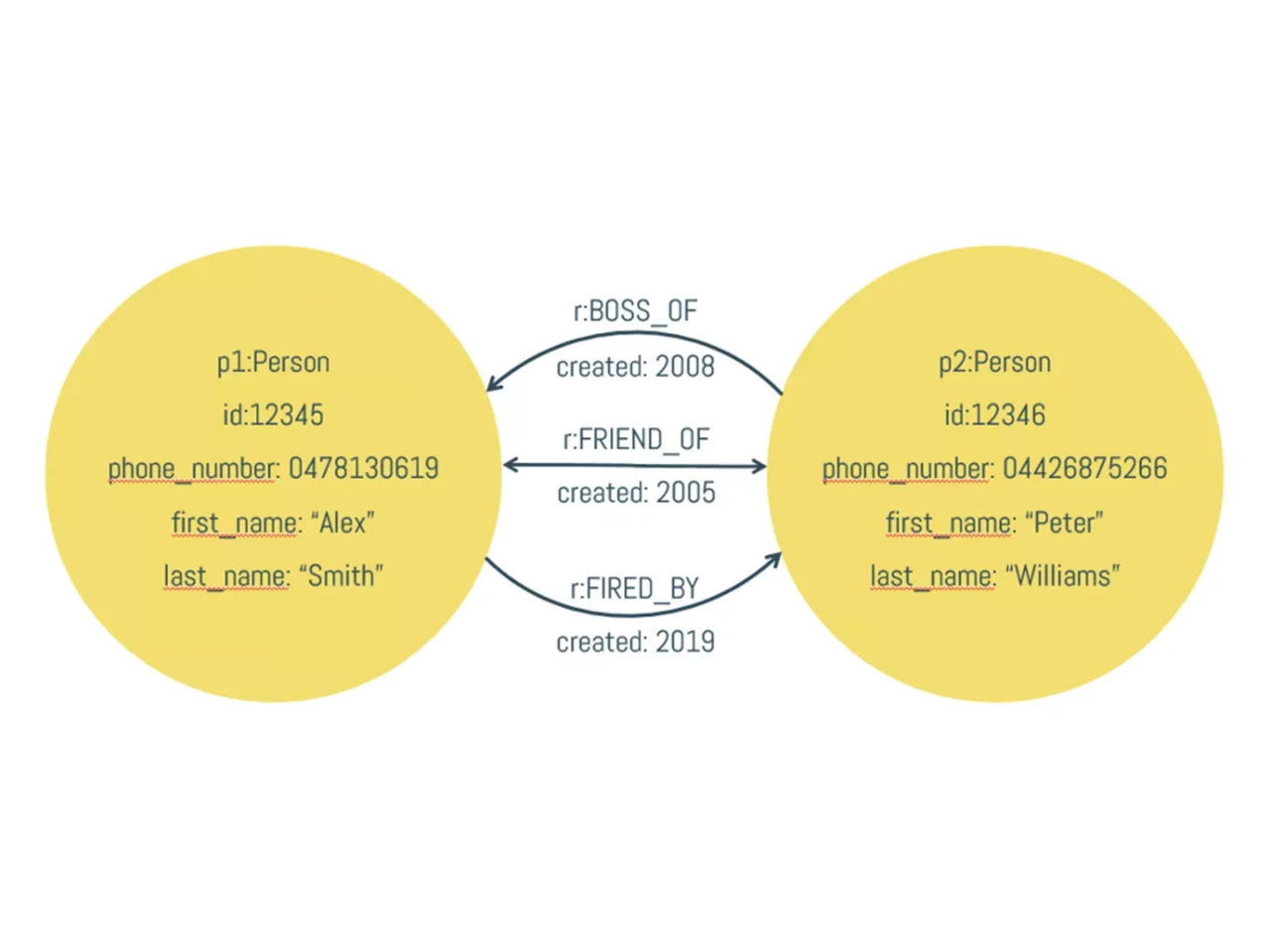
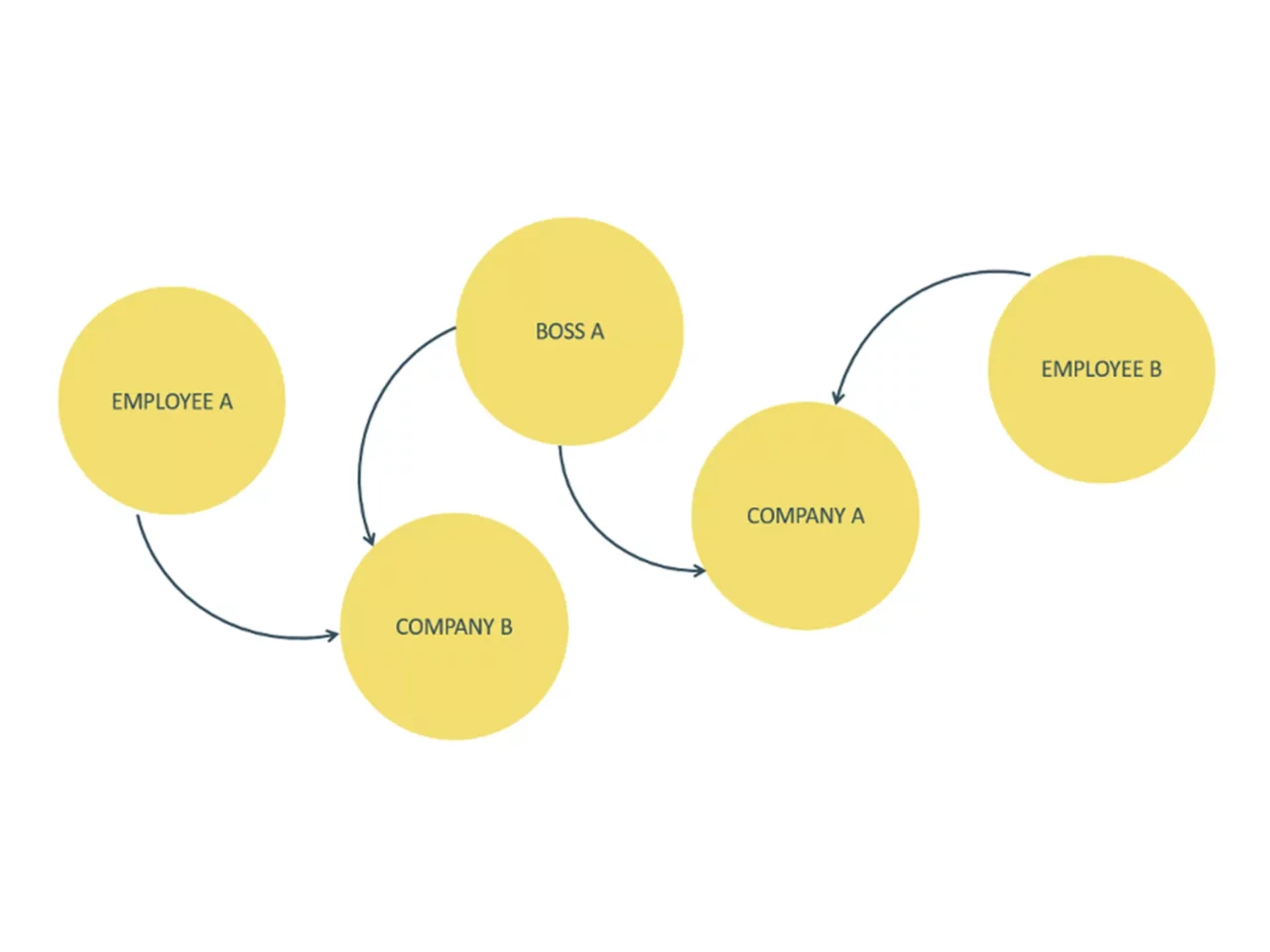
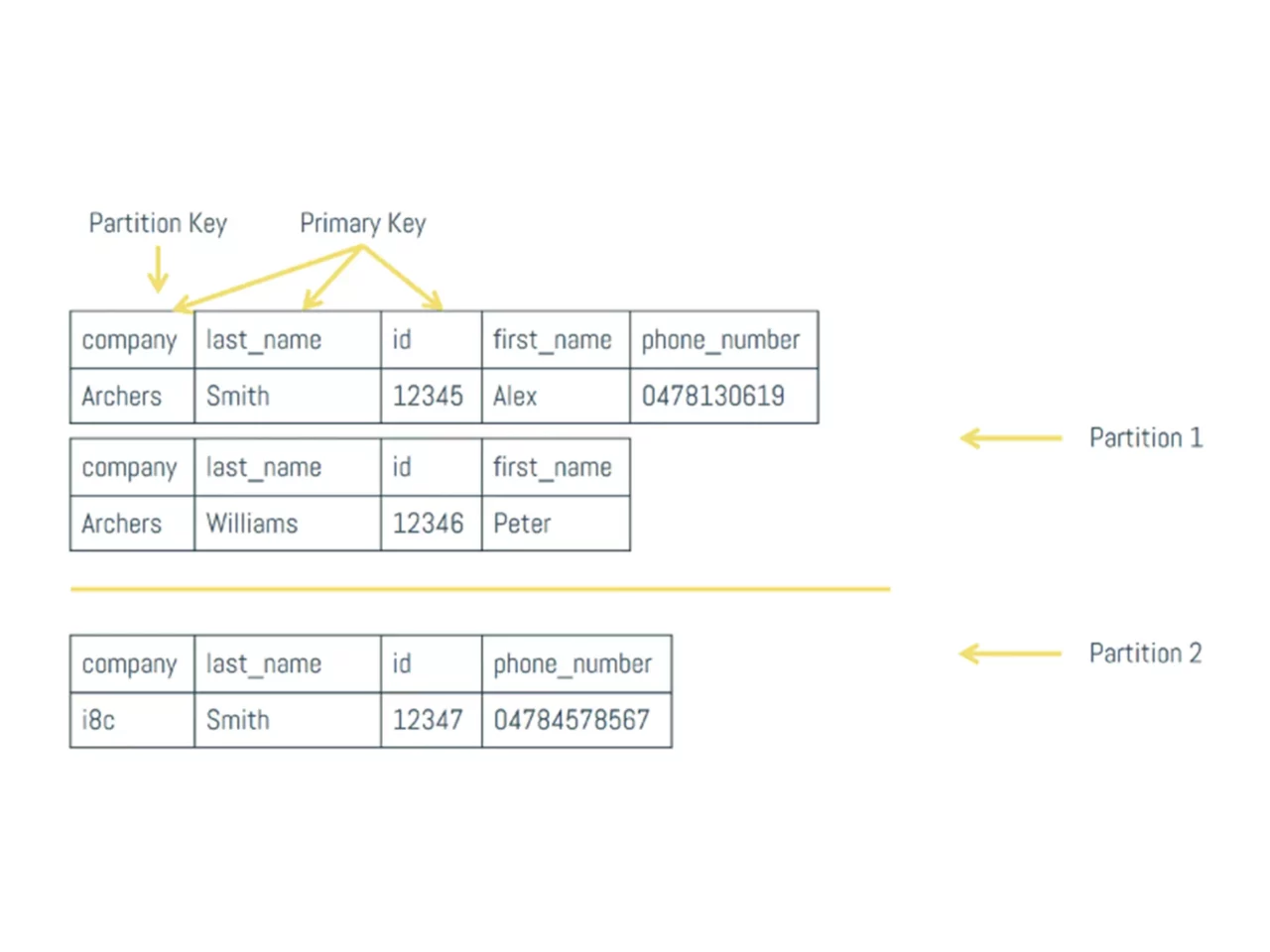
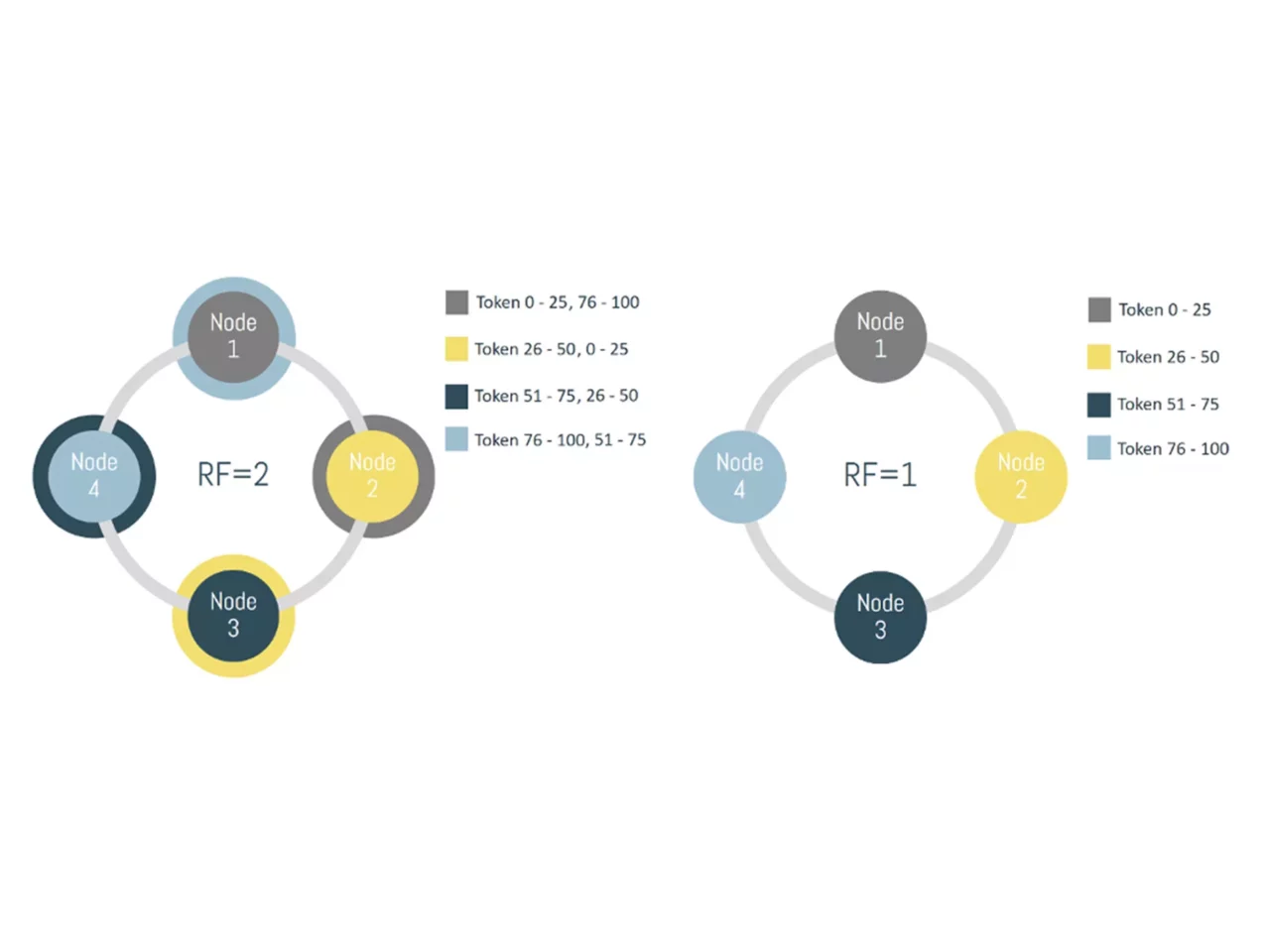
A practical example might clear things up. Let’s assume that we have 4 servers in a datacenter that each run one database node. In the first image, we are not replicating our data, so each node actually holds a fourth of all available data. We represented the token ranges in percentages, as the actual possible token ranges are pretty large and inconvenient to work with.
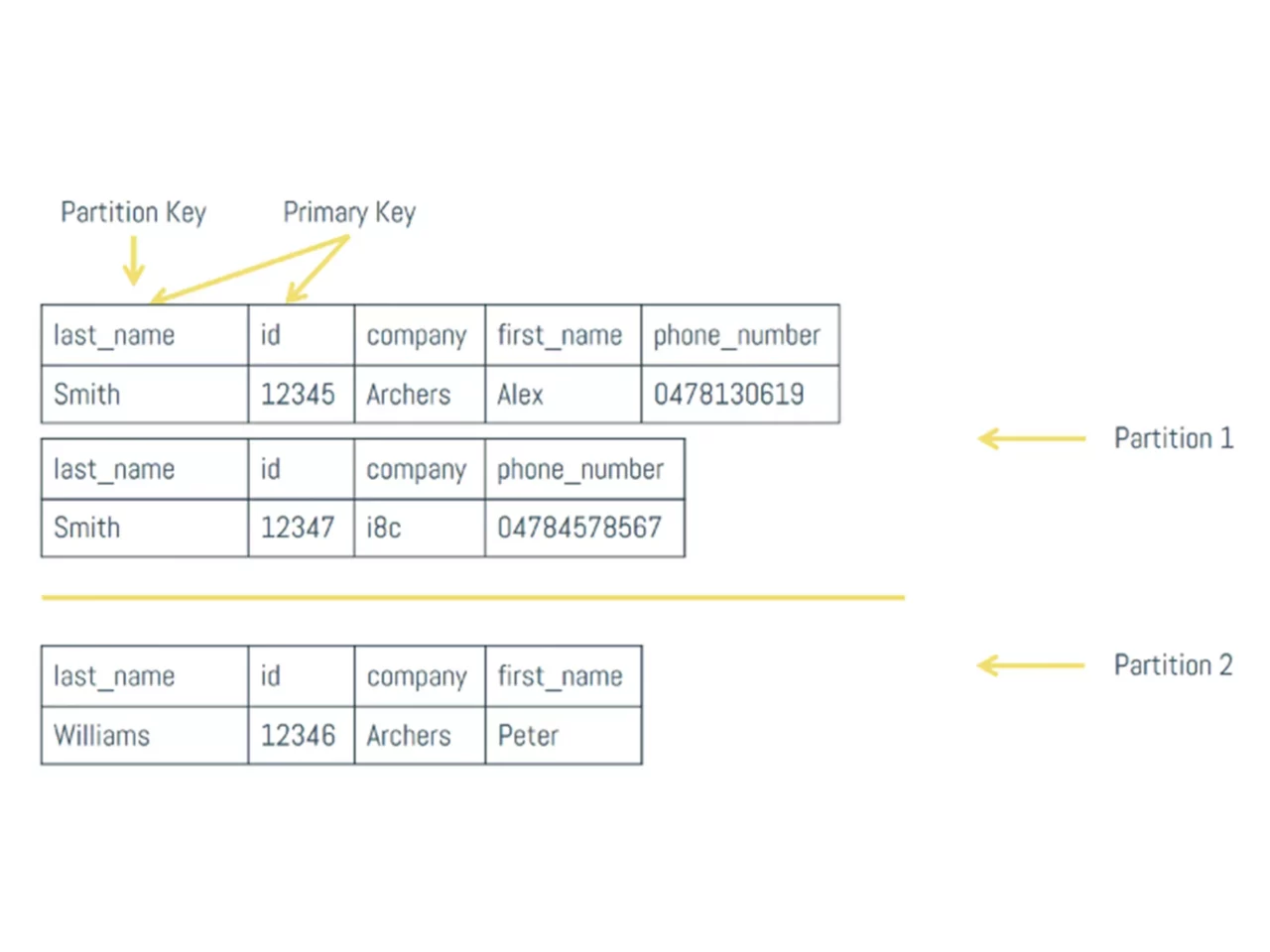
Think back at our first denormalized view, where we made company the partition key. If a consumer asks Node 1 to return all employees that work for Archers and Archers translates to a token value of 28, Node 1 knows that it needs to go looking for it in Node 2. After it gets the answer, it just passes it along to the consumer, pretending that it knew the answer all along.
Cassandra has a flexible replication factor, so the second image explains what would happen if we chose to duplicate data by factor 2. Now the same data can be found on 2 nodes. Image 1 is obviously not a realistic scenario. What if a node goes down? Your data might be inaccessible or worse, lost. Always build your systems for failure.
This built-in functionality is where Cassandra really shines. Your database can’t handle the load? Just add a node. Cassandra does everything else. Each individual node only has to carry a small part of the full load on the database. Due to the known storage place of each token range and the fact that each node can act as a Partitioner, you never need a full cluster scan to get what you need. It scales linearly incredibly well. Something that definitely cannot be said from a conventional database. You really need some incredible loads to outpace most SQL databases these days though. So do not make this choice lightly, because the architectural investment is not to be underestimated.
With your data spread over different nodes, multiple datacenters, perhaps even continents, concerns about performance start popping up. You don’t want to read each single node that has parts of the data you need and wait for them to respond. Cassandra has something called a tunable consistency to alleviate those concerns.
In theory, you could choose a consistency level for each individual read. Perhaps you don’t really care about consistency at all? In that case, you could only require the response of a single node. You could even wait for a response of all nodes that have your requested data, but of course, performance will drop significantly. Even then, you won’t always be fully consistent. Which response do you pick if not all responses are equal?
This goes for writing too. A write could be marked successful as fast as a single node received the data. This allows for very fast writes, but at the same time you would immediately after require a much slower read to be sure your data is consistent. Cassandra’s tunable consistency is great in allowing you to find something that’s exactly right for your use case.
There’s something called quorum read, which sounds like a happy medium for most. In a quorum read, the coordinating node sends out a request to all nodes that have the requested data. However, it only waits for at least 51% of them to respond. If your replication factor were 5 for example, the coordinating node waits for 3/5 of the nodes to respond.
If the data from those three nodes respond with is not consistent, it chooses the response with the most recent timestamp. This does not guarantee consistency, but it comes very close.