Micro services architectures come up with several advantages: a faster time to market, more flexibility and improved scalability and resilience. Micro services are simpler, developers get more productive and systems can be scaled quickly and precisely, rather than in large monoliths.
Yet, micro service architectures introduce new challenges as the complexity you removed in simplifying your micro services did not disappear. In this article, we zoom into the challenge of data islands/consistency. You will learn why this problem arises and what it is. We go deeper into what Event Sourcing and CQRS are and how they might solve this problem, if applied correctly.
The Autonomy Principle
One of the fundamental principles of microservice design is autonomy. If you’ve read Pat Helland’s 2005 paper about data on the inside vs data on the outside, this should sound familiar. This implies that each micro service needs to have its own data store. The main reason for this is the fact that when a change occurs in one of the data models, every service that depends on the shared database is impacted. Although this sounds logical, it is easier said than done. There are many cases where we rely on “external” data.
Imagine we’ve adhered to the autonomy principle. Suppose we have separated the data and now have data in one micro service (for example orders) that has a reference to data in another micro service (for example customer). In our shared database, we would query the data by simply joining the tables without any issues. Also handling transactions was no big issue as transaction management was properly handled in one place. However, the distributed nature of our micro services requires a different approach.
The Distributed Join
One thing we could do to solve this issue is by just directly querying the other micro service via a HTTP REST API call. Although we could easily do this, it leads to coupling of both micro services. In fact, we are performing a distributed join over HTTP and before we know it, we’ve created a distributed monolith.
To overcome this issue, we can duplicate the relevant data. Again, this could be done by simply issuing a command to the responsible micro service to update the reference via a HTTP REST API call. For example, the order micro service commanding the customer micro service to update the reference. In order to keep the data consistent we should also update the data atomic. We could make use of distributed transactions via a 2-phase commit. However, this is not recommended as the 2-phase commit is synchronously (a blocking operation). In a single database, transactions are fast. But due to the distributed nature of micro services, the delay will be longer.
We could solve this problem by implementing the Saga pattern: the distributed transaction is fulfilled by asynchronous local transactions on all related micro services. If any microservice fails to complete its local transaction, the other microservices will run compensation transactions to rollback the changes.
Although this is a commonly used pattern to solve transactional problems within the micro services world, in this blog we examine Event Sourcing with Event Driven Architecture as an alternative.
Event Driven Architecture
In short, the micro service subscribes to events which are published by another micro service to a message broker. Advantages of communicating via events are that we reduce coupling and resilience by design. There are new challenges though. First, when we have several subscribers, which data should we add in the payload of our domain event? Second, how can we atomically update the data and publish events?
Let’s take the example of the customer and order: suppose the customer micro service already updated the customer data but the event is not published to the broker, or the other way around: the event is published but the data cannot be updated. This can lead to inconsistencies.
Event Sourcing
Event sourcing is a data management pattern. With event sourcing, every state change is persisted as a journaled event in an append-only store (known as event-store). This could be something like Kafka for example. The current state is calculated by replaying and applying the history of events. This is different than the traditional databases (Active record) which continuously updates the current state.
This implies that every event will be stored in a single operation, which makes it atomic. As events are only ever appended, immutability can be guaranteed. If there is a failure in the transaction, the failure event is also added to the store.
THE PROS AND CONS OF EVENT SOURCING
Event sourcing has the following benefits, as well as some drawbacks:
- Benefits
- It solves one of the key problems in implementing an event-driven architecture: how to atomically update the database and publish events. It makes it possible to reliably publish events whenever state changes.
- Because it persists events rather than domain objects, it mostly avoids the object relational impedance mismatch problem.(ORM impedance mismatch)
- It makes it possible to implement temporal queries that determine the state of an entity at any point in time.
- It provides a 100% reliable audit log of the changes made to a business entity
- Event sourcing-based business logic consists of loosely coupled business entities that exchange events. This makes it a lot easier to migrate from a monolithic application to a micro service architecture.
- Drawbacks
- Event sourcing is a paradigm shift. Developers need deprogramming. It is a different and unfamiliar style of programming and so there is a learning curve.
- The Event Store is difficult to query
- The event store is difficult to query since it requires typical queries to reconstruct the state of the business entities. That is likely to be complex and inefficient.
- To solve this, we can use Command Query Responsibility Segregation (CQRS) to implement queries.
- This in turn means that applications must handle eventually consistent data.
- Out of order events
- Multi-threaded applications and multiple instances of applications might be storing events in the event store. The consistency of events in the event store is vital, as is the order of events that affect a specific entity (the order that changes occur to an entity affects its current state).
- Versioning
- If the format (rather than the data) of the persisted events needs to change, perhaps during a migration, it can be difficult to combine existing events in the store with the new version. It might be necessary to iterate through all the events making changes so they’re compliant with the new format or add new events that use the new format. Consider using a version stamp on each version of the event schema to maintain both the old and the new event formats.
- Replaying events can take a while when there are a lot of events
- This can be avoided by taking snapshots
GLOBAL EVENT SOURCING: SHARED DATABASE
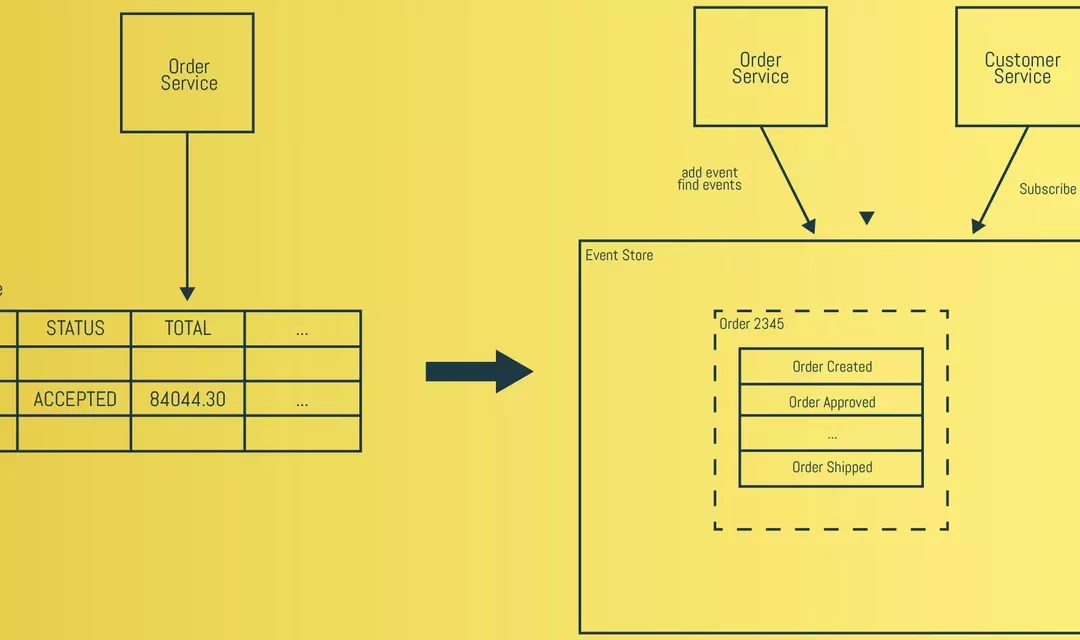
Let’s use our example of the customer and order micro services once more. As we can see in the picture below, on the left side we see the traditional database that stores the current state. The right side of the picture shows the implementation of event sourcing. Instead of storing the current state of the order in a row, the order is persisted as a sequence of events. The customer micro service can subscribe to the order events and update its own state. This way, we don’t have to worry about the payload of the event, as discussed earlier.
")
In the sample above, it is done with a global event store: one event-store where all the events for every microservices are stored.
This setup with a global event-store is something I’ve came across in examples on the internet as well as at customers. When I started with Event Sourcing, I implemented it like this as well. However, if we look closely at the picture above, we see that in fact our persistence is shared globally.
As stated earlier, Event sourcing is a persistence strategy. It doesn’t matter if we share events or databases, both must adhere to the autonomy principle. Basically, we’re back with what we started with, but now with (a lot) more complexity.
GLOBAL EVENT SOURCING: USING DOMAIN EVENTS
I still argue that an Event Driven Architecture is a good way to decouple the micro services, but the published events should not be the same as the (internal) events used for (local) event sourcing. Instead of having a shared global persistence, I propose to use a global event store to only store the public events. This way, the public events are shared and not the internal events.
Having dedicated domain events makes it possible once more to model these events differently than the internal model. Just like we have a contract for a REST API, we can define an interface for our public/domain events. This way the domain events which define the public model are no longer depending on the model you need for your internal persistence, so the public model can evolve independently of the internal implementation.
LOCAL EVENT SOURCING
Another benefit of having dedicated public events is that the local strategy can be current-state (a database) or Event Sourcing. If we choose to use Event Sourcing in our micro service, the local events are stored in our local event store which is only internally accessible. The benefit of having a local event sourcing strategy remains: the internal events are persisted and since they are immutable, we can observe these and publish them any time we want without having to worry about consistency.
CQRS
One of the drawbacks with Event Sourcing is that is hard to query. To overcome this issue, we can integrate CQRS with Event Sourcing. CQRS stands for Command Query Responsibility Segregation. With CQRS we have two different models that are separated from each other: one to change information (command) and one to read information (query). The command model is handled by the event-store, and the read model can be a completely other denormalized, materialized, read-optimized view based on the events. The advantages of having separate models and services for read and insert operations are:
- Load is distributed between command and query operations.
- Query (and Command) operations can be faster as the command and query services are optimized.
- The read model can differ from the command model.
The two biggest drawbacks of separating the responsibility of commands and queries are:
- Additional infrastructure.
- Added complexity in order to maintain and sync both the read and write side.
Conclusion:
At first glance, Event Sourcing seems to be the silver bullet for Event Driven Architectures. Just add a global event store and write your events to it. But if you pay attention, you realize that it can lead to a tightly coupled distributed system. It also adds complexity to your solution: when using Event Sourcing, CQRS is almost inevitable due to the nature of event sourcing and the need to query data.
We therefore recommend to use this pattern with care. Some typical use cases of Event Sourcing are:
- Heavy regulated environments where auditing is important. For example, banks, financial trading and insurance.
- Environments where historical data and analytics are important. Examples are government agencies and judiciaries where they need to keep huge amounts of data for years and have to apply business rules that where applicable at the time the events occurred.
- Environments where tracking is important, like shipping, freight and logistics.
ALWAYS LOOKING FORWARD TO CONNECTING WITH YOU!
We’ll be happy to get to know you.



